With structured entities
- AI processes your entity data efficiently
- Verified entities ground AI responses in facts
- High confidence = higher citation frequency
Call us at +1-408-200-2211 or fill the form below
*Required Files
Your privacy and security are a top priority. We will not distribute or sell your personal information to any third parties. Please visit our privacy policy page to contact us to review or delete data collected.
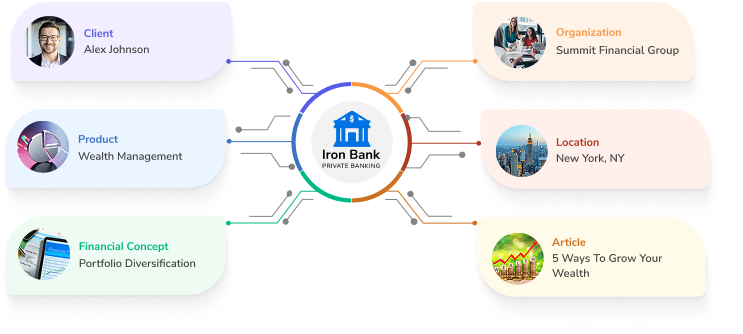
Every AI system has a limited compute budget. When your data is unstructured, AI spends that budget guessing who you are and whether to trust you. When your entities are structured and linked, it spends that budget choosing you instead.
The result: structured entities get cited more often. Milestone Schema Manager builds that machine-readable representation of your brand and keeps it current.
Milestone Schema Manager crawls up to a million pages and classifies every entity type automatically: locations, products, services, FAQs, events, and more. No setup required.



AI engines validate real-world accuracy before recommending a brand. Hours, addresses, service areas, pricing, availability: these are not just local SEO signals. They are entity properties machines verify before they trust and cite you.
For multi-location brands, each branch, advisor, or property needs to be its own linked entity with consistent data across every channel. Inconsistency creates ambiguity, and ambiguity lowers your odds of being selected.
A keyword is a string of text and a page is a document. An entity is a distinct thing in the real world, your organization, a product, a location, a person, a service, with its own identity and properties that machines can reason about. AI engines do not match strings anymore. They resolve things and the relationships between them, which is why optimizing entities, not keywords, is what now determines whether a business is understood and cited.
Read more in the AI Visibility Guide: Ch 2 From Strings to Things | Ch 5 Step-by-Step Entity Optimization
They perform entity resolution: matching identifiers, names, addresses, and cross-references to decide whether separate mentions describe one thing. A persistent identifier, the @id, plus sameAs links to authoritative records, lets an engine resolve you with precision instead of guessing. Without those anchors, the same business can fracture into several weak, competing entities, which lowers the confidence an engine needs to cite you.
Read more in the AI Visibility Guide: Ch 6 The Trust Layer | Ch 2 From Strings to Things
Within accuracy, more is better, and this is one of the most persistent myths to correct. Each valid property is another signal and another customer question your data can answer directly inside an AI response. Thin schema that lists only required fields leaves most of those questions unanswered, so a competitor with deeper, fully populated entities gets selected instead. The limit is truth, not volume: every property must reflect what the page actually says.
Read more in the AI Visibility Guide: Ch 4 Schema Myths Debunked | Ch 5 Step-by-Step Entity Optimization
Gaps force inference, and inference is where misattribution and hallucination begin. When a property is absent, an AI engine either fills it from a third-party source you do not control or declines to cite you because confidence is too low. Either way you lose the answer. Complete, validated properties remove that ambiguity and give the engine enough verified detail to choose your business safely.
Read more in the AI Visibility Guide: Ch 10 Data Validation | Ch 3 Building the AI Grounding Layer
It matters a great deal, because the long tail is exactly where many AI queries land. Manual tagging tends to favor a few high-traffic pages and leaves the rest thinly covered, creating large blind spots in your entity coverage. Applying the same depth of structured data to every page means AI engines find equally strong signals wherever a query resolves, which widens the range of questions you can be cited for.
Read more in the AI Visibility Guide: Ch 5 Step-by-Step Entity Optimization | Ch 7 Automation, Governance, and TCO
These are among the sources AI engines treat as trusted reference points, so a sameAs link to them acts as external corroboration of your identity. When your own structured data agrees with what an authoritative record says, the engine's confidence rises and the chance of a confused or incorrect answer falls. Each corroborating source strengthens your position in the citation networks AI engines rely on, and that trust compounds.
Read more in the AI Visibility Guide: Ch 6 The Trust Layer
Identity continuity is governed by your persistent @id rather than your display name, which is why the identifier is the foundation of machine trust. Maintaining the same @id while updating names, sameAs links, and properties lets AI engines carry your established authority across the change instead of treating the new name as an unknown entity. Handled poorly, a rebrand can reset the trust you have spent years building.
Read more in the AI Visibility Guide: Ch 6 The Trust Layer | Ch 10 Data Validation
Your privacy and security are a top priority. We will not distribute or sell your personal information to any third parties. Please visit our privacy policy page to contact us to review or delete data collected.
Call us at +1-408-200-2211 or fill the form below
*Required Files
Your privacy and security are a top priority. We will not distribute or sell your personal information to any third parties. Please visit our privacy policy page to contact us to review or delete data collected.