Learn More About Milestone Solutions
Call us at +1-408-200-2211 or fill the form below
*Required Files
Your privacy and security are a top priority. We will not distribute or sell your personal information to any third parties. Please visit our privacy policy page to contact us to review or delete data collected.
Schema Myths Debunked
If Chapter 3 introduced the concept of the Content Knowledge Graph (CKG) as the foundational architecture for AI grounding, this chapter confronts the common industry belief that undermines this entire effort: the "Myth: Schema doesn't work." This myth is rooted not in a failure of structured data itself, but in a failure of implementation quality.
The distinction between effective and ineffective Schema is simple: implementation quality matters. Organizations that see zero performance benefit often stop at basic, fragmented markup, which is insufficient to communicate the clarity and relationships required by modern generative models.
The belief that "schema doesn't work" persists because schema is consistently evaluated against the wrong success criteria. Most organizations expect schema to behave like a ranking factor, a traffic lever, or a short-term optimization tactic. When those outcomes fail to materialize, schema is dismissed as ineffective.
In reality, schema is not designed to create demand, rankings, or guaranteed visibility. Its primary function is to reduce ambiguity, establish entity clarity, and improve eligibility for enhanced results across search and AI systems. When schema is measured by traffic or rankings alone - rather than by eligibility, confidence, and machine comprehension - it will almost always appear to "fail," even when implemented correctly.

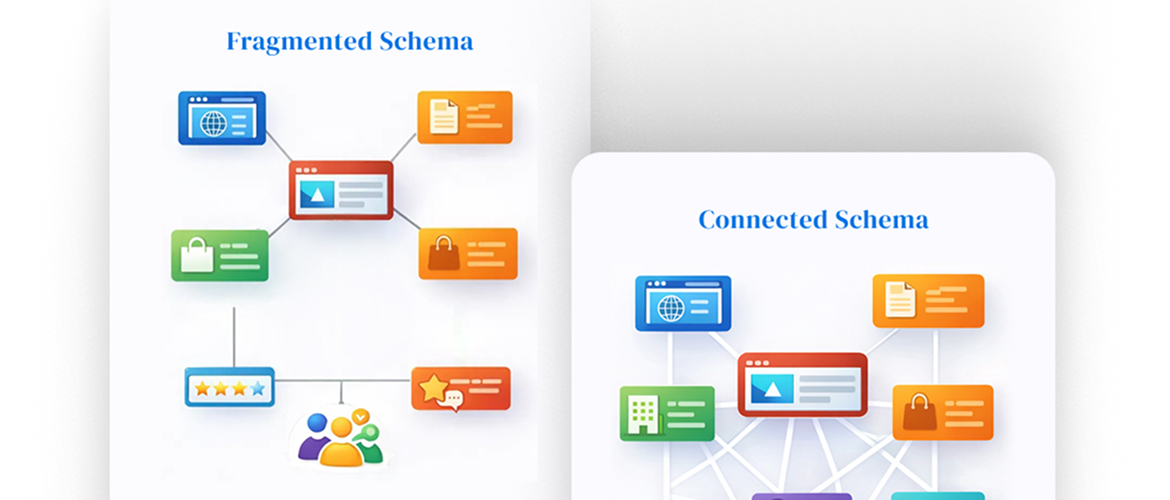
The Limitation of Basic, Fragmented Markup
When SEO professionals implement basic schema, they typically create separate, isolated markups for multiple entities on a single page, such as tagging a Product, an Organization, breadcrumbs and an AggregateRating individually. This approach creates fragmented data and does not effectively assist AI systems in understanding the relationship between entities in your content.
- Missing context: Specifying each entity separately misses the opportunity to clearly communicate hierarchy and explicit relationships between components to search engines.
- Forcing inference: When data is fragmented, machines must infer critical relationships. For example, search engines may be unable to determine whether reviews and ratings apply to a specific product or to the organization selling it. This ambiguity increases cognitive load and introduces uncertainty into the AI grounding process.
- Validation does not equal optimization: Passing Rich Results tests and schema validators confirms syntactic correctness and Schema.org compliance, but does not ensure improved entity understanding or reduced inference cost for AI systems. As a result, many sites pass validation while still publishing fragmented, ambiguous, or computationally expensive structures that provide little practical value.
- Exhausting the comprehension budget: Ambiguous structures force AI systems into costly inference loops to cross-verify facts, rapidly consuming the comprehension budget and reducing the likelihood that the content will be selected as an authoritative, low-cost source.
Why Fragmented Schema Fails in AI-Driven Selection Systems
Modern search engines and generative AI systems operate under economic constraints. Each additional inference required to resolve entity relationships increases the computational cost of using that source. Fragmented schema structures force AI systems to reconcile facts across disconnected entities, increasing uncertainty, and consuming limited comprehension of resources.
When equivalent information is available elsewhere with clearer structure and lower inference cost, AI systems will preferentially select those sources. In this context, fragmented schema does not merely underperform - it actively disqualifies content from competitive selection.
The consequence is clear: basic markup may enable foundational identity recognition, but it fails to build the relational structure necessary for deep entity awareness and eligibility for the most valuable, context-rich results.
Why Schema Does Not Guarantee Rich Results
Another common misconception is that implementing schema guarantees rich results. In practice, schema establishes eligibility, but it is not an entitlement. Rich results represent scarce; competitive inventory, and search engines apply additional selection criteria beyond markup presence, including entity confidence, historical consistency, and cross-signal corroboration.
Pages with shallow or ambiguous schema may technically qualify for rich results, but they often lose selection priority to sources with clearer entity lineage and lower ambiguity. The absence of a rich result is therefore not evidence of schema failure, but of insufficient structural confidence.
The Mandate for Deep Nested Schema and Entity Optimization
The only effective solution is to move beyond fragmented tags to embrace deep nested Schema and entity optimization. Deep nesting is the mandatory practice of structuring your markup hierarchically by grouping relevant secondary entities under a defined main entity of the page.
This methodology ensures that relationships are explicit and undeniable:
- Clarified hierarchy: Structuring entities in a clear hierarchy enables search engines to better understand the properties associated with your defined entities and their interrelationships. For example, on a Product page, the AggregateRating entity should be nested as a property of the main Product entity, explicitly indicating that the review relates to that specific product rather than the general brand.
- Building a robust Content Knowledge Graph (CKG): This explicit relational structure is fundamental to building a strong CKG and establishing entity awareness. Nesting schema makes the graph interconnected, enabling AI systems to gain new factual knowledge through logical inferencing.
Deep nesting is not simply about embedding additional attributes into markup, but about expressing the full lineage of entities associated with a business in a machine-readable way.
In practical terms, deep nesting enables AI systems to understand upstream-to-downstream relationships, such as an Organization creating a Brand, the Brand manufacturing a Product, the Product belonging to a Category, and that Category serving a specific purpose or use case.
By fully nesting entities - for example, Organization > Brand > Product > Offer > PriceSpecification > Review > Person - brands are not merely describing a page but publishing a closed-loop knowledge graph that models the business with precision.
The more explicit these relationships are, the less an AI system must infer, the lower the comprehension cost, and the higher the confidence score assigned to the content.
This is how deep nesting moves schema from a collection of facts on a page to a trustworthy, machine-resolved representation of reality that modern AI systems prefer to cite and recommend.
The Competitive Advantage of Error-Free Structure
The success of advanced schema is not theoretical; it is measurable. Research by Milestone confirmed that rich media search results have increasingly displaced traditional plain links, making the accurate mapping of content to user intent dependent on semantic clarity.
Schema failures are frequently attributed to markup mechanics when the true cause is organizational timing and ownership. In most enterprises, schema is applied late in the content lifecycle - after URLs, templates, and messaging have already diverged across teams and markets.
At this stage, schema cannot correct structural inconsistencies; it can only reflect them. Without upstream governance, entity ownership, and template-level integration, schema becomes decorative rather than corrective, reinforcing existing ambiguity instead of resolving it.
Milestone research found that sites utilizing "error-free advanced schemas" materially outperformed sites with no schemas in SEO visibility, non-brand share, and overall traffic:
- SEO visibility, non-brand share, and traffic increase materially with error-free advanced schema compared to having no schema.
- Entity markup helps search engines clarify content and facts, improving search relevance, particularly for universal and rich results.
This evidence confirms that the depth, correctness, and completeness of implementation are critical factors in achieving a positive impact. Proper, deep nesting minimizes ambiguity and maximizes the likelihood of content selection in the era of generative AI.
Guidance from Milestone on Overcoming Schema Failure
The necessary implementation framework requires a comprehensive approach, prioritizing the relational architecture over mere quantity of tags. Review the expert guidance on proper structural integrity in How to Implement Schemas Correctly:
- Proper format: Generate schema markup using the JSON-LD format, paying close attention to the recommended and required elements.
- Nesting mandate: Proper nesting is crucial to building entity awareness and a comprehensive knowledge graph.
- Comprehensive approach: Maximize the benefits by adopting a comprehensive deployment strategy that includes research, proper formatting, deployment, ongoing management, and measurement.
The next chapter details the practical, five-step playbook for transitioning your site from basic, fragmented tags to a deeply nested, authoritative entity framework.
All Chapters
Your privacy and security are a top priority. We will not distribute or sell your personal information to any third parties. Please visit our privacy policy page to contact us to review or delete data collected.